Varför en Telugu tecken brickar Apple-enheter
Apple har haft en buggy några månader. Nu har vi en ny, allvarlig bugg i texthanteringsfunktionen i iPhones. Felet utlöses av en enda Telugu-tecken som kan orsaka att en iPhone går in i en obruten startslinga bara genom att ta emot en anmälan som innehåller tecknet. Låt oss gräva på varför en enda karaktär kan orsaka sådana stora problem med iOS.
Obs! En fix för Telugu-buggen finns tillgänglig i den senaste versionen av IOS (11.2.6). Om Telugu-tecknet har låst upp din app eller enhet, återställ din iPhone via iTunes och uppdatera till den senaste versionen av IOS. Om din iPhone är fast i en startslinga kan du behöva lägga den i DFU-tillståndet (Device Firmware Update) för att få iTunes att känna igen det. När du är klar ska du återställa enheten från din senaste säkerhetskopia, vilket du förhoppningsvis skapade.
Vad är telugu?

Telugu är ett språk som talas och skrivs i delar av Indien, speciellt staterna Andhra Pradesh, Telangana och i staden Yanam. Liksom många scriptbaserade språk, som arabiska och andra Brahmic-skript, använder Telugu några speciella funktioner i Unicode teckenuppsättningen för att visa dess tecken på en datorskärm.
Medan de flesta latinska bokstäverna representeras av en singel 8-bitars Unicode-kodpunkt för ASCII-kompatibilitet (till exempel finns bokstaven A vid Unicode-kodpunkten U+0041, som representeras i binär av 01000001 ), språk skrivna med manus eller icke- Latinska bokstäver kombinerar vanligtvis mer än en Unicode-kodpunkt för att representera deras karaktärer.
Detta gäller särskilt för språk, som telugu, som kombinerar språkversionerna av bokstäver i kluster. Till skillnad från Engelska stilistiska ligaturer är anslutningen mellan varje Telugu-brev språkligt viktig. För att tillgodose detta, innehåller Unicode ett komplext system för att bifoga tecken, var och en representerad av sin egen kodpunkt, till varandra.
Med tanke på det stora antalet Unicode-kodpunkter kan detta skapa nära oändlig variation. Dessa punkter kombineras för att göra en läsbar karaktär. På så sätt behöver Unicode inte en Unicode-kodpunkt för bokstavligen alla möjliga Telugu-ord. I stället kombinerar Unicode Telugu-konsonanter, vokaler och diakritiker ("virama") tillsammans för att skapa ord som visas som en enda karaktär. Detsamma gäller för andra språk med ortografiska regler för ligaturer, som arabiska.
Vad orsakar kraschen?

Problemet verkar vara relaterat till Zero Width Non-Joiner (ZWNJ) vid kodpunkt U+200C . ZWNJ begär att två intilliggande tecken gör sig utan sin typiska ligatur. På engelska håller en ZWNJ tecknen ff från att skrivas ut med sin standardanslutningsligatur, istället separera varje f. Men i kombination med en specifik uppsättning av fyra telugu-kodpunkter (som alla ska kombinera till ett enda kluster), kan iOS av någon anledning inte visa resultatet korrekt.
Några har spekulerat att Apples San Francisco-teckensnitt inte kan visa karaktären, medan andra har sagt att den specifika reningsprocessen Apple använder är skyldig. Oavsett den exakta orsaken orsakar försöket att göra karaktären en dramatisk krasch av vad som än gör det, från meddelanden och WhatsApp till Springboard. Unicode-koden pekar på som utgör karaktären ("gya" som betyder "kunskap") är nedan:
U+0C1Cja (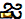 )
)U+0C4Dett virama- eller diakritiskt märke ( )
)U+0C1Enya (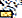 )
)U+200Cej sammanslagnaU+0C3Eaa (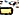 )
)
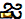 )
) )
) )
) )
)Men vi kan inte ens skylla Zero Width Non-Joiner (ZWNJ) ensam. Det används också i den oskyldiga familjen emojis (????) Utan några problem. Det verkar vara en specifik kombination av vissa specifika kodpunkter och ZWNJ. Att lägga till förolämpning mot skada verkar som om ZWNJ heller inte har någon särskild inverkan på rendering på detta telugu-kluster eller att det inte ens skulle vara där i första hand.
Andra Brahmic Script Problem
Telugu är inte det enda språket med det här problemet. Bengali och Devanagari, som använder Unicode på samma sätt för deras Brahmic-skript, har samma problem. Manish Goregaokar skriver ett fasctinerande och detaljerat blogginlägg som bryter ner det exakta kraschfallet ännu längre:
Vilken sekvens som helst
i Devanagari, Bengali och Telugu, där:1.
consonant2ärpstf(pstf/vatu)
2.consonant1är inte en reph-forming letter
3.vowelhar inte två glyf-komponenter
Slutsats: Varför blev inte detta fångat av Apple?
För att förstå hur det här felet kom igenom måste du sätta dig i Apples skor. Visst, denna kombination av tecken är inte något super obskilt ord på telugu-språket. Men iPhone innehåller stöd för dussintals språk. Det finns bokstavligen miljarder potentiella kombinationer i Unicode. Med den stora variationen, meningsfull testning av Unicode-fel innan en release skulle göra regelbundna mjukvaruuppdateringar i princip omöjliga.
Felet borde dock inte ha orsakat så mycket skada. Telefoner får inte bli murade baserat på innehållet i ett textmeddelande. Medan efterhand är säkert 20/20 verkar det som att göra tecknet som en frågeteckenlåda ( ) skulle ha varit bättre än att krascha Springboard.





![Så här byter du teckensnittet i WordPress 3.2 HTML Editor [Snabbtips]](http://moc9.com/img/wp-new-editor-font.jpg)
